
LinksTamed SEO Tool
Extension Actions
- Live on Store
Проведите аудит сайта: рассчитайте статический вес страниц, найдите частичные дубликаты, технические ошибки и плохие тексты.
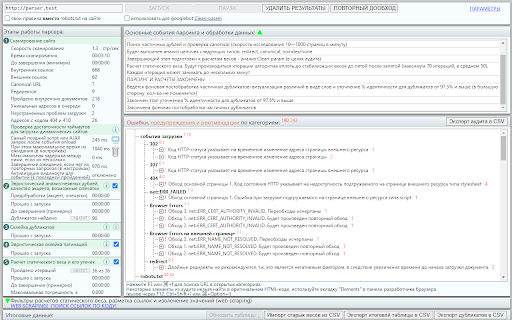
LinksTamed - это полнофункциональный парсер для аудита сайта, который позволяет проверить распределение статического веса, оценить качество текстов, найти частичные дубликаты, провести аудит технических ошибок и многое другое.
Вы сможете узнать, попадает ли на продвигаемые страницы нужное количество статического веса, т.е. какой авторитет среди прочих внутренних страниц сайта они имеют и наоборот, что второстепенные страницы не получают лишнего. Помимо этого, контролируйте утечку веса из-за исходящих ссылок и тех адресов, которые закрыты от индексации, а также находите ошибки в структуре сайта и самих ссылках. Значение статического веса документа также показывает вероятность попадания на него пользователя с других страниц сайта. И этот момент будет важен всегда.
Повышенная точность расчетов достигается благодаря загрузке динамического контента страниц через вкладки приватного окна браузера, что позволяет чувствовать себя увереннее со сторонними скриптами на сайте!
♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️
Что же умеет этот парсер?
Очевидное:
✔️Подсчет статического веса страниц сайта;
✔️Информация по каждой исходящей и входящей ссылке;
✔️Сопутствующий аудит сайта;
✔️Учет директив robots.txt с сайта или добавление собственного;
✔️Учет meta тегов и директив X-Robots-Tag, rel=nofollow/ugc/sponsored;
✔️Сохранение в .CSV и выгрузка старых весов из .CSV.
В основной таблице вы можете посмотреть статический вес страниц, утечки веса, сколько утекающего веса можно сохранить, добавив одну ссылку и сколько веса передаст одна новая ссылка со страницы.
LinksTamed также осуществляет поиск частичных дубликатов и найдет все наиболее похожие документы, а также проверит имеющиеся Canonical и Clean-param. Кроме того, парсер автоматически склеит все достаточно похожие страницы и отвечающие условиям страницы пагинаций, а также разбитые на страницы тексты, чтобы вы могли видеть более реалистичную структуру сайта и распределение статического веса.
Особого внимания заслуживают различные метрики для оценки текста на каждой странице, включая оценку его качества и релевантности ключевым тегам, а также проверка наличия релевантного TITLE-заголовку страницы описания изображения.
В LinksTamed также имеется функционал Web Scraping, который позволяет сохранять нужные поля со страниц сайта, включая файлы, а также даёт возможность размечать ссылки, в том числе для их дальнейшей фильтрации и перерасчётов статического веса. И это в дополнение к множеству других фильтров.
♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️
В последней версии появились следующие возможности:
✔️Аудит множества проблем, связанных со структурными тегами, такими как SECTION, ARTICLE и т.п.;
✔️Проверка иерархии и допустимости использования заголовков H1-H6;
✔️Аудит атрибута LANG в теге HTML и автоматическое определение языка страниц сайта с проверкой его сочетаемости с LANG;
✔️Аудит сложных проблем связанных с тегом BASE.
♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️
В недавних версиях появились следующие возможности:
✔️Проверка уникальности TITLE, Description и первого H1 страницы относительно других страниц сайта;
✔️Оценка релевантности текста относительно избранных алгоритмом ценных слов из TITLE-заголовка страницы, Description, первого тега H1 с выставлением оценки от 0 до 10 в основной таблице, а также расшифровкой в виде избранных слов;
✔️Выставление оценки наиболее релевантному TITLE-заголовку описанию картинки в атрибуте ALT и расшифровкой по избранным словам;
✔️Отображение в таблице с результатами текста из Мeta Description и первого заголовка H1-заголовок страницы, а также их длины, включая предупреждение о превышении рекомендуемых длин в аудите;
✔️Более детальные метрики для проверки описания страницы в Meta Description: длина первого предложения в Meta Description, а также отображение максимальной длины при наличии nosnippet max-snippet и предупреждение, если они обрезают Description;
✔️количество тегов H2 на страницах;
✔️Продвинутый поиск по данным, включая логические условия И и ИЛИ, а также разноцветную подсветку результатов поиска.
♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️
Список остальных возможностей LinksTamed:
✔️Поддержка HTTPS протокола, www2 и т.д.;
✔️Поддержка адресов с доменами и адресами на основе любых национальных алфавитов;
✔️Поддержка SPA, PWA и т.п. JS сайтов с динамическим контентом;
✔️Естественный обход в пределах домена или мультидоменный парсинг по списку;
✔️Проверка на конфликты X-Robots-Tag и meta директив;
✔️Аудит ошибок в robots.txt, включая подробный пакет рекомендаций;
✔️Учет правил директивы Clean-param из robots.txt и аудит конфликтов;
✔️Учет canonical всех видов, включая Link HTTP header;
✔️Проверка работоспособности canonical, в том числе схожести контента, оповещение о нестандартных ситуациях и отмена недействительных канонических рекомендаций;
✔️Эвристическая склейка пагинаций и её сочетаний с каноническими рекомендациями и дубликатами;
✔️Учет любых редиректов, включая серверный, meta (в т.ч. с задержкой) и JS, оповещение о возможных проблемах, циклических, двойных и многократных редиректах;
✔️Полная загрузка страниц до события onload, отработка скриптов и рендеринг, учет ссылок типа "a href", созданных JavaScript;
✔️Возможность не только учесть правила для робота, но и представиться сайту поисковым ботом;
✔️Поиск ссылок без анкоров, различных ссылок-картинок без анкора в виде alt с выводом списков в аудите;
✔️Определение типа файла из его content-type;
✔️Проверка всех ссылок ресурсов на доступность (внутренних и внешних), включая изображения в srcset;
✔️Эвристической поиск сообщений об ошибках серверных скриптов в контенте страниц и поиск фрагментов испорченного JavaScript-кода в видимом тексте;
✔️Вывод предупреждений, если в HTML-коде много комментариев и подключаемых ресурсов;
✔️Графы для оценки текста на каждой странице: «всего слов», «% слов без повторов» и новая метрика «качество акцента», которая позволяет оценить документ с точки зрения дополненной ценности его текста, т.е. насколько уникальный смысл текста обогащает сайт в целом;
✔️Вывод списка словоформ встречаемых 1 раз на сайте для последующей проверки орфографии;
✔️Предупреждения о смешанном контенте: ресурсы с http на страницах с протоколом https;
✔️Уровень вложенности от главной;
✔️Справочный подсчет количества iframe (вес не передают и не получают);
✔️Поддержка древних frame;
✔️Передача статического веса файлам, которые принимают вес (pdf, xml, doc и т.п.);
✔️Вывод в таблице кол-ва входящих на страницу ссылок передающих вес, а также nofollow;
✔️Графа в таблице - входящие на страницу ссылки: обычные, nofollow (+ugc и sponsored);
✔️Настраиваемое количество потоков парсинга: каждый поток использует свое ядро процессора для выигрыша в скорости;
✔️Учет ошибок зависания и любых других ошибок в процессе загрузки, безопасная выгрузка из памяти страниц с зависшими скриптами, деблокирование диалоговых окон;
✔️Возможность исключать ссылки на страницы и сайты из расчетов и провести оценку весов в определенной области на сайте, например, между карточками товаров;
✔️Работа с весом висячих узлов (dangling nodes) - страниц и файлов индексируемых типов, не имеющих исходящих ссылок – вес таких тупиковых документов распыляется по всем узлам сайта. Ссылки на другие документы также являются висячими узлами и возвращают часть своего веса;
✔️Рекомендации по оптимизации рендеринга, включая предупреждения о слишком длинных или не умещающихся по ширине страниц;
✔️Проверка URL-адресов на длину и мусорные фрагменты;
✔️Предупреждение, когда страница не закрыта от индексации и при этом не имеет исходящих ссылок;
✔️Использование прокси-сервера, указанного в настройках браузера;
✔️Сотни других проверок.
♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️
Минимальные системные требования:
- Разрешение экрана: 1024x600;
- 3Gb ОЗУ.
При парсинге сайта с более чем 50 тысячами страниц или 1 400 000 ссылок необходимо не менее 3Gb ОЗУ и ОС 64-bit.
МАКСИМАЛЬНОЕ КОЛИЧЕСТВО СТРАНИЦ с контентом 110 000, но не более 15 миллионов ссылок в сумме.
На время парсинга и расчетов отключается функция спящего режима. После парсинга устройству разрешается уснуть уже с готовым результатом.
♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️
Анонимность: В исходном коде отсутствует вообще какой-либо функционал для передачи данных иным лицам.
♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️♊️
Оптимальные настройки уже выставлены, просто начинайте парсинг! Все виды данных будут подсчитаны автоматически и выведены в таблицу внизу главной страницы.
Latest reviews
- Sergey Kolnogorov
- Работало. А вот недели как 3 не работает. Не хочет сканировать висит на старте и всё. Проверьте, пожалуйста.
- Степан
- Блин - вот это крутая Штука! Как же хорошо что я её нашёл, причём чисто случайно! Спасибо за разработку - будем вникать и изучать!
- Виктор
- Добавил инструмент в свой базовый инструментарий для аудитов. Пользуюсь регулярно, нареканий никаких.
- dstv installer
- but can someone teach me how to read russian
- dstv installer
- but can someone teach me how to read russian
- Филипп Попов
- караул! после запуска парсера, он зациклился и 0 страниц уже больше 3 часов "анализирует" при этом ни остановить и ничего вообще не сделать... https://clip2net.com/s/44EoSMW походу надо будет переустанавливать плагин...
- Anton Maltsev
- Самое полезное расширение для хрома!
- Denis Maramygin
- Удобный инструмент, тем более работает в браузере. Класс, спасибо!
- alexander sokolov
- Ого Спасибо!!!
- Sergei Shtykalov
- Хороший инструмент, пожалуй первое расширение для парсинга сайта через браузер которым буду пользоваться. +Было бы круто задавать исключения для парсинга категорий.