
Image Reader (OCR)
Extension Actions
- Extension status: Featured
- Live on Store
Easily get words out of an image with OCR engine!
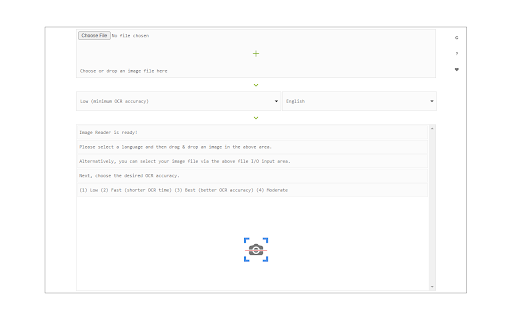
Image Reader (OCR) extension helps you easily get words out of any image. It uses two different open-source OCR engines.
The 1st engine is called Tesseract. Tesseract.js is an open-source JavaScript library and is made via an Emscripten port of the famous Tesseract OCR Engine written in C and C++. Please visit (https://github.com/naptha/tesseract.js) to get more info. The 2nd engine, called Granite Docling, is developed by IBM (https://huggingface.co/ibm-granite/granite-docling-258M). Please note that when you choose IBM Granite Docling, the app needs to download training data (~1200MB) for the AI engine. So please be patient while it is loading.
To work with this addon, simply open the addon's interface and load your image via the file selector (top section). Before using the addon, please make sure to select the appropriate OCR engine and language. For Tesseract, the default OCR language is set to English. For Granite Docling, you do not need to set a language; just select the desired backend (CPU or GPU) and wait for the app to load completely.
Note: For the Tesseract OCR engine, this addon uses the "https://github.com/naptha/tessdata/tree/gh-pages/" GitHub repo to fetch language data required for the OCR operation. For the IBM Granite Docling, it uses "https://huggingface.co/onnx-community/granite-docling-258M-ONNX" to fetch training data required for the OCR operation. Both language data packs are very large and cannot be included in the addon package.
To report bugs, please fill out the bug report form on the extension's homepage (https://mybrowseraddon.com/image-reader.html).
Latest reviews
- Polar Torsen
- It's dumb. I thought this would allow to select a part of the screen, but instead it opens a window and asks to upload a file. This is just retarded. Two stars for making something that at least works, eventhough so unconveniently.
- Rupam Mondal
- Best OCR
- Isaac Moore
- Needs a way to take information from the clipboard. It would be ideal if we could also take snips of websites.
- Vasquez
- Bazı kelime ve cümleleri düzgünce okuyamıyor ve aktaramıyor, kullanışsız
- Diamond Dream
- its great
- Diamond Dream
- its great
- Ayman Mahrous
- the best
- Ayman Mahrous
- the best
- Gokey 517
- Using it for things where you cant copy paste the information in a reading that a teacher gives to cite information, it works great. Make sure you set it to the best setting before trying to translate otherwise it comes out as random words. (Pretty sure the other reviews didn't do this before giving up on it). I haven't tested it on harder to read text styles, but basic textbook text styles come out decently with the 1% chance a word is messed up. The only other issue is it doesn't copy paste cleanly they add 'enter' spaces at the end of each line to make it flow exactly like the picture so when copy pasting it into word or a google doc you have to clean them up, but otherwise it works.
- Gokey 517
- Using it for things where you cant copy paste the information in a reading that a teacher gives to cite information, it works great. Make sure you set it to the best setting before trying to translate otherwise it comes out as random words. (Pretty sure the other reviews didn't do this before giving up on it). I haven't tested it on harder to read text styles, but basic textbook text styles come out decently with the 1% chance a word is messed up. The only other issue is it doesn't copy paste cleanly they add 'enter' spaces at the end of each line to make it flow exactly like the picture so when copy pasting it into word or a google doc you have to clean them up, but otherwise it works.
- Sobon George
- Useless.
- Sobon George
- Useless.
- FiloWay
- çok iyi
- Dusty Bawls
- AMAZING it does miss spell like a super small percentage of letters not whole words only letters in alot of languages thanks alot
- Dusty Bawls
- AMAZING it does miss spell like a super small percentage of letters not whole words only letters in alot of languages thanks alot
- 年奥齐
- 不支持中文么?识别出来全是乱码
- Thảo Nguyễn Thu
- thời gian nhận dạng chữ hơi lâu, mình mất khoảng 50 giây để nhận dạng 1 ảnh
- Guo guo
- It would be perfect if you add a screenshot function
- Guo guo
- It would be perfect if you add a screenshot function
- shko hamid
- thanks this is best
- shko hamid
- thanks this is best
- Shawn McLaughlin
- Makes everything unreadable
- Shawn McLaughlin
- Makes everything unreadable
- محسن ملاجان
- please add farsi (persian)!!! Thanks.
- GB L
- Very Great! It can support a variety of languages. It also works separately from chrome.
- GB L
- Very Great! It can support a variety of languages. It also works separately from chrome.
- smoke big
- The accuracy of Chinese character recognition is not very high.
- smoke big
- The accuracy of Chinese character recognition is not very high.
- Augusto Buechler
- Image Reader is a perfect OCR add-on. And now, with drag and drop, it's even easier to use.
- Augusto Buechler
- Image Reader is a perfect OCR add-on. And now, with drag and drop, it's even easier to use.
- Ahmet Bülent Dönmez
- An extremely nice add-on. Thank you so much.
- Ahmet Bülent Dönmez
- An extremely nice add-on. Thank you so much.