
Wuispa
Extension Actions
- Extension status: In-App Purchases
- Live on Store
Gather, tranform, share any kind of data in any format from any website via a point and click interface.
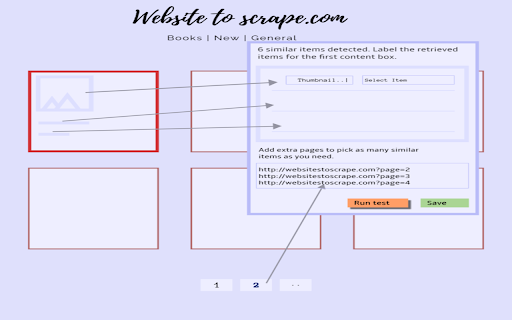
Wuispa is a GUI based web scraper that allows anyone to gather data from any website without any coding(programming) knowledge.
It works by allowing the user to select pages and the specific content blocks required from the page. The scraper then loops through each of the items and makes a list of each. The items are retrieved into a list that can be exported as csv, json or consumed by the REST API.
This extension only serves to aide in selection of required items from the content blocks that the user desires to extract data from. It enables reading the element paths so that the scraper can do the same and extract all similar items. The actual processing/scraping is done by a python program that matches the selected elements by launching a headless chrome browser. It currently runs on heroku platform.
Wuispa is cloud based and runs as a SaaS, i.e the user pays for the data extracted at the dashboard which can be accessed via the url: https://wuispa.com/dashboard. The extension itself does not need any billing from the user to operate. And it also does not need any configuration. It simply runs the jQuery code that is used to pick required items from the DOM.
Why we built another GUI scraper?
Not all the existing scrapers are easy to use. Some even require waiting periods to try them out while some require credit card information but wuispa only requires user's email address for authentication after which they can try it right away.
Another advantage is that wuispa requires no learning to use. The interface is a point-and-click and anyone can do it. The elements found in any of the desired content blocks are automatically retrieved and the user simply needs to label the ones they need.
This ensures as fewer mistakes as possible when labeling data for example, price and title fields for eCommerce products can be difficult to pick with precision manually when using other scrapers that don't retrieve every visible element automatically.
With wuispa the user can also follow links in the content blocks to extract the information from those detail pages as well. For example, you can gather products and their long description at the details page with little configuration. This ensures you extract as much information as is needed.
Wuispa gathers data by assimilating human browsing, this means the websites scraped do not suffer DOS attacks. We put a limit such that if you're scraping 10 pages from a site, they are not all done at once but sequentially so the user can just wait for the data as it runs in the background.
Wuispa also aims at data tranformation in the next releases where the gathered data can be translated, figures can be modified by fixed values or percentages and so on.