
NoCoding Data Scraper - Easy Web Scraping
Extension Actions
- Extension status: Featured
- Extension status: In-App Purchases
- Live on Store
Einfaches Browser-Automatisierungs- und Web-Scraper-Tool. extrahiert Daten aus HTML-Webseiten in Excel-Tabellen oder Google Sheet
+ Arbeiten Sie mit dem Verifizierungscode-Erkennungs-Plug-in (https://chromewebstore.google.com/detail/captcha-solver-free-auto/hlifkpholllijblknnmbfagnkjneagid) zusammen, um jedem Bedürftigen die Möglichkeit zu geben, komplexe Verifizierungscode-Herausforderungen während der automatischen Prüfung zu lösen Sammelprozessfähigkeit.
Ein einfacher No-Code Web Scraper mit nur 3 Klicks!
Sofortige KOSTENLOSE Rezepte als E-Mail-Crawler, Web-Scraping-Tool und Business-Lead-Scraper von Zielwebsites!
Instant Data Scraper mit KI-Datenerkennung und Datenextraktion mit einem Klick von jeder Website!
Weitere Web-Extraktions- und Web-Scraping-Funktionen für die Registrierung!
Web-Scraping-Tool für automatische Paginierung ohne Code für verschiedene Paginierungsszenarien!
Automatische Scraping-Rezeptgenerierung und visuelle Scraping-Rezeptbearbeitung.
Alle extrahierten Daten werden sicher lokal mit doppeltem Schutz gespeichert
einfacher Webcrawler, der geplante Aufgaben automatisch ausführt
WAS IST EIN EASY WEB SCRAPER ODER WEB CRAWLER?
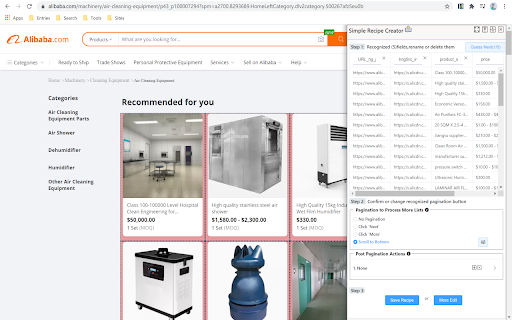
NoCoding Data Scraper (NDS) ist ein einfaches Daten-Scraping-Tool zum Scrapen von Webdaten. Öffnen Sie einfach eine Webseite, lassen Sie NDS die tabellarischen Webdaten und die Paginierungsschaltfläche automatisch erkennen und teilen Sie dem Scraping-Tool mit, dass vor oder nach der Web-Extraktion automatisch weitere Aktionen ausgeführt werden sollen und geplant.
Ein einfacher Web-Scraper kann auch ein Image-Scraper oder ein Image-Crawler sein, um die Bild-URL direkt zu extrahieren. NDS unterstützt das Scrapen von Bildern im Stapel und das Herunterladen der Bilder in die lokale oder Remote-Cloud.
WIE SIEHT EIN LEISTUNGSFÄHIGER WEBSCRAPER AUS?
NDS unterstützt Sie beim intelligenten Extrahieren von Elementinhalten mit Selektoren und unterstützt mehrere Paginierungsmodi, wie z Daten über mehrere Websites über den Pipeline-Modus.
Online-Video-Tutorials: https://www.youtube.com/channel/UCvcBbUXf_0Zj5_JR5U5n-MA
Kernfunktionen:
• Deep Web Scraping und automatisches Web Crawling
• Web-RPA zur Automatisierung des Klickens von Elementen, der Dateneingabe und der Webextraktion
• Automatische Generierung von KI-gestützten Web-Scraper-Rezepten
• Web-Scraper und Web-Crawler für das URL-Scraping im Batch
• Web-Scraper für Suchmaschinenabfragen und Ergebnis-Scraping
• Web-Scraper mit Unterstützung für einfache Paginierungsmodi
• Unendlich scrollendes Web-Scraping
• Web-Scraper mit flexibler Datenumwandlung und -verfeinerung
• Web-Scraper mit iFrame-Content-Scraping-Unterstützung
• Image Extractor und E-Mail-Crawler zum lokalen oder Cloud-Speicher
• Web Scraper für dynamisches Content Scraping (JavaScript + AJAX)
• Inkrementelles Scraping und Crawling von Daten
• Integration mit Google Sheet, Slack und anderen Anwendungen von Drittanbietern
• Keine technischen Fähigkeiten für 99% Schabearbeiten erforderlich
• Live-Support, Remote-Rezept-Debugging-Unterstützung und benutzerdefinierte Rezeptentwicklung
Einige häufige Anwendungsfälle:
* Scraping von Geschäftskontakten, E-Mail-Finder oder Scraping von öffentlichen Telefonen in wenigen Minuten für Verkauf, Immobilienmakler und Makler
* Preisüberwachung und Bewertungsüberwachung für Amazon-Verkäufer, Distributoren und Bewertungsanalysten
* E-Mail-Scraping, Adressen-Scraping und Telefon-Scraping aus öffentlichen Verzeichnissen für Freiberufler
* Dateneingabeautomatisierung und Datenextraktion intelligent für die Arbeit von zu Hause aus
* Bewertungen und Rezensionen, die Websites für Kleinunternehmer abkratzen
* Web-Scraping-Tool + SEO-Tools für SEO-Profis
* auf der Suche nach Bewerbern als Zeitplan für Personalvermittler
WIE FUNKTIONIERT NDS?
Scraper ist ein Datenextraktor und -konverter, der E-Mails oder jeden anderen Text von öffentlichen Webseiten sammeln kann. NDS unterstützt Sie bei der Definition von Rezepten und Aufgaben, indem es den CSS Selector verwendet, um die Informationen auf der HTML-Seite zu identifizieren. Dann kratzt es diese Informationen als Zeitplan und speichert das Ergebnis in Ihrem Browser in Form einer Tabelle, die Sie später als CSV- oder XLSX-Datei speichern können NDS unterstützt UTF-8, so dass es Englisch,日本语(Japanisch),русский(Russisch),中文(Chinesisch),한국어( Koreanisch) usw. Es sind keine Python-, JavaScript-, JSON- oder xPath-Kenntnisse erforderlich, um das Tool zu verwenden.
Unterschied zwischen WEB SCRAPER und WEB EXTRACTOR:
Normalerweise sind die Funktionen von Web Scraper ähnlich wie die von Web Extractor. Beide dienen zum Scrapen oder Extrahieren von Inhalten aus der Webseite. Hier hilft NDS nicht nur beim Scrapen von Daten, sondern bietet auch Funktionen zum Extrahieren, Transformieren und Bereinigen von Daten. .
Kann NDS als E-Mail-Crawler arbeiten?
Ja. Es gibt viele kostenpflichtige E-Mail-Crawler. NDS bietet eine E-Mail-Scraping-Methode zum kostenlosen Sammeln öffentlicher E-Mails. In Zusammenarbeit mit der benutzerdefinierten Google-Suchmaschine (CSE) können Sie No-Code-Rezepte definieren, um öffentliche E-Mails einfach aus den CSE-Suchergebnissen zu extrahieren.
Kann NDS als Business Lead Scraper arbeiten?
Ja. NDS kann gut als Lead-Scraper arbeiten. Sie können Rezepte zum Ausfüllen von Schlüsselwörtern definieren und dann Lead-Informationen aus öffentlichen Suchergebnissen herauskratzen.
Ist NDS ein RPA?
RPA (Robotic Process Automation) ist ein beliebtes Konzept, mit dem Benutzer Bots definieren können, um eine Serienaktion automatisch auszuführen. Anders als Desktop-basierte RPA-Tools ist NDS eher ein browserbasiertes Automatisierungstool oder Web-RPA. Außer Scraping können Sie Definieren Sie verschiedene Aktionen, um das Scrollen, Klicken auf Elemente oder das Eingeben von Feldern zu simulieren, um die Arbeit zu erleichtern und eine hohe Produktivität zu erzielen.
IMPORTANT INFO:
PRIVACY
NoCoding Data Scraper(NDS) is a web scraping tool. All scraped data is always PRIVATE and visible only to you. Whether you're using our free or paid plans, NDS
* DOES NOT KEEP your scraped data or websites account information (except the account you used to login the tool if registered),
* DOES NOT STORED OR SEND your scraped data to our servers,
* DOES NOT SHARE your scraped data with anyone without your explicitly agreement.
NDS uses your own computer (browsers), and runs as an browser extension that lives only in your browser. Nothing scraped leaves your computer.
NDS DOES NOT SCRAPE any data anonymously. The scraper strictly follows the recipe you defined or imported.
More information about Privacy Policy, please refer to NDS's official website: https://www.minirpa.net
DATA PROTECTION AND SECURITY
NDS ENCRYPTS all exported recipes for you, and registered users can ask to set operational pin code for DUAL PROTECTION.
Your email address is used for login and notification purposes, and will NEVER be provided to others for any purposes without your explicitly agreement. NDS transmits your account information over HTTPS with additional AES encryption algorithm.
NDS requires you to understand and abide by the terms of use of whatever site you are scraping and that the user generated recipes are there for you to use “as is” without any obligation from NoCoding Data Scraper to modify or fix them or to help you to use them.
ADDITIONAL INFO:
Following Chrome extension permissions are required to run the NDS:
activeTab: required to track active tab for the creating of recipe
WebNavigation: required to track the tabs opened when scraping multiple pages
storage: required to store scraped data and configuration
unlimitedStorage: required to store all scraped data for exporting later
notification: required to notify you when tasks done
More permissions are required for some specific features, and NDS will ask for permission grant via the browser when corresponding features enabled.
Please let us know if you have any feedback or feature requests:
[email protected]
Or contact us via our official website:
https://www.minirpa.net
Latest reviews
- Sagi Brown
- Charged me falsely 35$ and wouldn't respond to my emails
- Bo Kjærgaard
- Seems connection to Google Sheets no longer work? The OAuth client was disabled on authentication
- Soufiane Ouakif Business
- 🔥You will feel like you have an AI that creates a workflow automation tools.🔥 Hi, I'm Soufiane, a Muslim from Morocco 🇲🇦, specializing in workflow automation through custom browser extensions. From auto-filling forms and performing repetitive tasks and scraping data, and more... I make your online work simpler and more efficient. **What Makes Us Stand Out?** With our expertise, you'll experience exceptional speed and efficiency in every project. We tackle even the toughest challenges and dedicate 100% of our focus to your task—no distractions. Our goal is not just profit but to free you from tedious tasks and ongoing costs, allowing you to focus on your major goals for quick, effective results. **Pricing Structure:** - Simple Projects: $50 - $100 - Medium Projects: $200 - $400 - Advanced Projects: $500 - $1000 - Monthly Subscription: $5k+ (for ongoing automation needs) # **How We Work:** - 1. Send us a video explaining the steps you want automated. - 2. We’ll analyze the project and provide an estimated price offer. - 3. We’ll develop the automation and send you a demo video. - 4. After payment, you’ll receive the final project. - 5. Lifetime VIP technical support. - 6. If you'd like, share your experience with us in a short video! - 7. We’ll be ready for your upcoming project requests! **We're Here for Any Inquiry!** - Have questions about automation or your upcoming project? Reach out, and we’ll respond quickly to provide the best solution for you. **Whatsapp for fast & direct contact : +212 628-330721**
- Duolinko Telbi
- The best one! Free version is enough for me.
- نـــدیم
- kindly fix the login issue
- Mahbub Rahman (Robin)
- A nice extension for scraping. But it is not completely free. Even then it works very well. In my case, sometimes it could not automatically go to the next page. It stopped after going to two pages. But, I tried again later. Then I was able to scrape up to many pages. But, again it stopped automatically after going to several pages. So I think it is a bug that needs to be fixed.
- Sunny
- Best from other scraping extensions, I scraped almost 750 movies data from IMDB in just minutes. Thank you for extension.
- TripleTree B. Hong
- really good. I tried several other add-ons, none of them extracted dynamic content completely except you. It would be better if there were more examples.
- Beyound Young
- Good extension
- Jacob Fenix
- Fantastic addon that's useless after one big scrape unless you pay an extortiate fee (and per month). Also requires you to sign up - should have been the first red flag. Avoid this one and find another.
- Katuki puong
- the new version is awesome!
- Anonymous
- nice. thanks
- Savage Susan
- Incredible tool and services. I can't code or use python. your YouTube videos helped me out. Plus plan is acceptable for me to scrape unlimited pages - worth it!
- sino House Thai
- Good
- tottooPatong
- Wow! the most powerful scraper! how to handle captcha during scraping?
- phofula kamala
- Great add-on and services, thank you Tracy.
- Kevin W
- Don't waste your time and money on it. It's a garbage. Poor documentation and no support.
- Anisur Rahman
- great extension.
- Anisur Rahman
- great extension.
- S Su
- 好用!
- Hoi Wai CHEUNG
- Only two columns of data can be extracted on the website, but the page display should be able to capture 8 columns of data. Why can’t this tool extract it? Site:www.valinonline.com
- Yuk Pui Joey TSANG
- If you don't register or log in, it is basically useless. Then you can use it for a while for free, and all subsequent functions will be charged, which is not worth it
- Kwok Yau KO
- There is no refund after payment, and the page crashes after a long time of crawling, so I don’t need this plugin anymore
- Manisha THAPA
- pourquoi ne peut-il pas être ouvert
- Rahul Kappor bhh
- It's too heavy to operate, and it charges, I can't use it anymore
- na li
- 真的特别好用!!!感谢了!!!
- cornercafebangkok
- Awesome. would be better if you support Safari.
- cornercafebangkok
- Awesome. would be better if you support Safari.
- chipotlle hnong
- By far the best addon!. There's 5 min learning curve at first. If you're familiar with HTML, CSS, it's extremely powerful and useful! Different from other scraper addon, this one can simulate manual surfing correctly, and handle various tricky cases. Kudos to you for making this!
- chipotlle hnong
- By far the best addon!. There's 5 min learning curve at first. If you're familiar with HTML, CSS, it's extremely powerful and useful! Different from other scraper addon, this one can simulate manual surfing correctly, and handle various tricky cases. Kudos to you for making this!
- Jesdaporn Jettrin
- the best data crawler. thank you team
- Jesdaporn Jettrin
- the best data crawler. thank you team
- Leon Rahmaan
- The best tool I have ever used to extract email address from pages. Easy to use, and best of all makes my work so much easier.
- Leon Rahmaan
- The best tool I have ever used to extract email address from pages. Easy to use, and best of all makes my work so much easier.
- Noam Hussain
- the tool is INTENSE AF, I'm using a free plan but the features feel un-right to be free. so time healing!
- Noam Hussain
- the tool is INTENSE AF, I'm using a free plan but the features feel un-right to be free. so time healing!
- Mushroom kids School
- awesome app and team. At first I just used it to collect public information and data from our own internal portal. Later, Tracy also guided me on how to automate my daily routine work. Now, the data collation and data entry tasks that I used to need two days a week now only take one hour to complete! It has unbelievably improved my work efficiency and allowed me to spend more time with my children. Thank you guys!
- Mushroom kids School
- awesome app and team. At first I just used it to collect public information and data from our own internal portal. Later, Tracy also guided me on how to automate my daily routine work. Now, the data collation and data entry tasks that I used to need two days a week now only take one hour to complete! It has unbelievably improved my work efficiency and allowed me to spend more time with my children. Thank you guys!
- 林凛
- 现在是无法登录了吗?都是403
- Yeshwant Bafna
- I dont have to mention more, everyone has already praised the product. But I must say more than the product, the team is just AMAZING. Their support and love and understanding of the product is outstanding. Just go for it and you will fall in love with the team and the product
- Yeshwant Bafna
- I dont have to mention more, everyone has already praised the product. But I must say more than the product, the team is just AMAZING. Their support and love and understanding of the product is outstanding. Just go for it and you will fall in love with the team and the product
- Carol kong
- 真的好强大!赞一个
- Joabe
- Looks good, but needs to create login. I hate having to create a new boring login.
- Joabe
- Looks good, but needs to create login. I hate having to create a new boring login.
- rouhao wang
- Pay carefully! Pay carefully! Pay carefully! Once paid cannot be refunded, some functions cannot be tested in the free version, and the plug-in crashes after running for about 5 minutes, which cannot be solved.
- rouhao wang
- Pay carefully! Pay carefully! Pay carefully! Once paid cannot be refunded, some functions cannot be tested in the free version, and the plug-in crashes after running for about 5 minutes, which cannot be solved.
- Fitness Equipment Haswell
- 建议把名称换成 “ minirpa迷你派采集器-最简单网页自动采集抓爬取监控” 方便搜索
- 陈俊钦
- 太强了, 居然是真的这么强, 太棒了
- Alexander Doak
- Fast support, really good functionality. In continual development, so it is improving over time. Some issues with data scraping stopping during internet outage, but they may be fixing that soon. Overall extremely useful. We have a paid subscription for almost a year now, and just upgraded to Pro.
- Alexander Doak
- Fast support, really good functionality. In continual development, so it is improving over time. Some issues with data scraping stopping during internet outage, but they may be fixing that soon. Overall extremely useful. We have a paid subscription for almost a year now, and just upgraded to Pro.