
Scraper de données sans codage - Scraping Web facile
Extension Actions
- Extension status: Featured
- Extension status: In-App Purchases
- Live on Store
Automatisation de navigateur simple et outil de grattage Web. extrait les données des pages Web HTML vers des feuilles de calcul…
+ Coopérer avec le plug-in de reconnaissance de code de vérification (https://chromewebstore.google.com/detail/captcha-solver-free-auto/hlifkpholllijblknnmbfagnkjneagid) pour offrir à toute personne dans le besoin la possibilité de résoudre des problèmes complexes de code de vérification lors de l'automatique. capacité de processus de collecte.
Un simple grattoir Web sans code en 3 clics seulement !
Recettes GRATUITES instantanées en tant que robot d'exploration d'e-mails, outil de grattage Web et grattoir de prospects commerciaux à partir de sites Web cibles !
Grattoir de données instantané avec détection de données AI et extraction de données en un clic depuis n'importe quel site Web !
Plus de fonctionnalités d'extraction et de grattage Web pour une inscription !
Outil de grattage Web de pagination automatique sans code requis pour divers scénarios de pagination !
Génération automatique de recettes de grattage et édition visuelle de recettes de grattage.
Toutes les données extraites sont stockées en toute sécurité en local avec une double protection
robot d'exploration Web facile exécutant automatiquement les tâches planifiées
QU'EST-CE QU'UN SCRAPER WEB OU UN CRAWLER WEB EASY ?
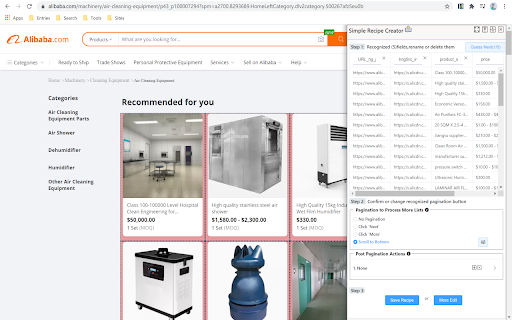
NoCoding Data Scraper (NDS) est un simple outil de grattage de données pour gratter des données Web. Ouvrez simplement une page Web, laissez NDS reconnaître automatiquement les données Web tabulaires et le bouton de pagination, et indiquez à l'outil de grattage des actions supplémentaires à exécuter avant ou après l'extraction Web automatiquement et programmé.
En outre, un grattoir Web simple peut être un grattoir d'images ou un robot d'exploration d'images pour extraire directement l'URL de l'image. NDS prend en charge le grattage des images par lots et le téléchargement des images sur un cloud local ou distant.
À QUOI RESSEMBLE UN RACLEUR WEB PUISSANT ?
NDS vous aide à extraire intelligemment le contenu des éléments avec des sélecteurs et prend en charge plusieurs modes de pagination, tels que cliquer sur le bouton suivant, cliquer sur le bouton Charger plus, cliquer sur la page une par une ou faire défiler infiniment vers le bas. données via plusieurs sites Web via le mode pipeline.
Tutoriels vidéo en ligne : https://www.youtube.com/channel/UCvcBbUXf_0Zj5_JR5U5n-MA
CARACTERISTIQUES de base:
• Extraction Web approfondie et exploration Web automatique
• Web RPA pour automatiser le clic sur les éléments, la saisie de données et l'extraction Web
• Génération automatique de recette de grattoir Web alimentée par l'IA
• Web scraper et web crawler pour le grattage d'URL par lots
• Web scraper pour les requêtes des moteurs de recherche et le grattage des résultats
• Web scraper avec prise en charge des modes de pagination facile
• Scraping Web à défilement infini
• Web scraper avec transformation et affinage flexibles des données
• Web scraper avec prise en charge du grattage de contenu iFrame
• Extracteur d'images et analyseur d'e-mails vers un stockage local ou cloud
• Web scraper pour le scraping de contenu dynamique (JavaScript + AJAX)
• Extraction et exploration de données incrémentielles
• Intégration avec Google Sheet, Slack et d'autres applications tierces
• Aucune compétence technique requise pour les tâches de grattage à 99 %
• Assistance en direct, assistance au débogage de recettes à distance et développement de recettes personnalisées
Quelques cas d'utilisation courants :
* Recherche de prospects, recherche d'e-mails ou de téléphones publics en quelques minutes pour les vendeurs, les agents immobiliers et les courtiers
* Suivi des prix et suivi des avis pour les vendeurs, distributeurs et analystes d'avis Amazon
* Récupération d'e-mails, d'adresses et de téléphones à partir d'annuaires publics pour les pigistes
* Automatisation de la saisie des données et extraction des données intelligemment pour travailler à domicile
* Notes et avis sur les sites Web croisés pour les propriétaires de petites entreprises
* Outil de grattage Web + outils de référencement pour les professionnels du référencement
* recherche de candidats comme emploi du temps pour les recruteurs
COMMENT FONCTIONNE NDS ?
Scraper est un extracteur et convertisseur de données qui peut récupérer des e-mails ou tout autre texte à partir de pages Web publiques. NDS vous aide à définir des recettes et des tâches en utilisant CSS Selector pour identifier les informations dans la page HTML. Ensuite, il récupère ces informations sous forme de calendrier et stocke le résultat dans votre navigateur sous la forme d'un tableau que vous pouvez enregistrer en tant que fichier CSV ou XLSX plus tard. NDS prend en charge UTF-8, donc il gratte l'anglais,日本语(japonais),русский(russe),中文(chinois),한국어( coréen) etc. Aucune compétence python, JavaScript, JSON ou xPath n'est requise pour utiliser l'outil.
Différence entre WEB SCRAPER et WEB EXTRACTOR :
généralement, les fonctions du grattoir Web sont similaires à celles de l'extracteur Web. Les deux consistent à gratter ou à extraire le contenu de la page Web. Ici, NDS aide non seulement à gratter les données, mais fournit également des fonctionnalités pour extraire, transformer et nettoyer des données. .
NDS peut-il fonctionner comme un robot d'exploration d'e-mails ?
Oui. Il existe de nombreux explorateurs d'e-mails payants. NDS fournit un moyen de récupération d'e-mails pour collecter librement les e-mails publics. En collaboration avec le moteur de recherche Google personnalisé (CSE), vous pouvez définir des recettes sans code pour extraire facilement les e-mails publics des résultats de recherche CSE.
NDS peut-il fonctionner comme un grattoir de prospects ?
Oui. NDS peut bien fonctionner comme un grattoir de prospects. Vous pouvez définir des recettes pour remplir des mots-clés, puis extraire des informations sur les prospects à partir du résultat de la recherche publique.
Le NDS est-il un RPA ?
RPA (Robotic Process Automation) est un concept populaire permettant aux utilisateurs de définir un bot pour exécuter automatiquement une action en série. Différent des outils RPA basés sur le bureau, NDS ressemble davantage à un outil d'automatisation basé sur un navigateur ou à un RPA Web. À l'exception du scraping, vous pouvez définir diverses actions pour simuler le défilement, le clic sur des éléments ou la saisie de champs pour rendre le travail facile et une productivité élevée.
IMPORTANT INFO:
PRIVACY
NoCoding Data Scraper(NDS) is a web scraping tool. All scraped data is always PRIVATE and visible only to you. Whether you're using our free or paid plans, NDS
* DOES NOT KEEP your scraped data or websites account information (except the account you used to login the tool if registered),
* DOES NOT STORED OR SEND your scraped data to our servers,
* DOES NOT SHARE your scraped data with anyone without your explicitly agreement.
NDS uses your own computer (browsers), and runs as an browser extension that lives only in your browser. Nothing scraped leaves your computer.
NDS DOES NOT SCRAPE any data anonymously. The scraper strictly follows the recipe you defined or imported.
More information about Privacy Policy, please refer to NDS's official website: https://www.minirpa.net
DATA PROTECTION AND SECURITY
NDS ENCRYPTS all exported recipes for you, and registered users can ask to set operational pin code for DUAL PROTECTION.
Your email address is used for login and notification purposes, and will NEVER be provided to others for any purposes without your explicitly agreement. NDS transmits your account information over HTTPS with additional AES encryption algorithm.
NDS requires you to understand and abide by the terms of use of whatever site you are scraping and that the user generated recipes are there for you to use “as is” without any obligation from NoCoding Data Scraper to modify or fix them or to help you to use them.
ADDITIONAL INFO:
Following Chrome extension permissions are required to run the NDS:
activeTab: required to track active tab for the creating of recipe
WebNavigation: required to track the tabs opened when scraping multiple pages
storage: required to store scraped data and configuration
unlimitedStorage: required to store all scraped data for exporting later
notification: required to notify you when tasks done
More permissions are required for some specific features, and NDS will ask for permission grant via the browser when corresponding features enabled.
Please let us know if you have any feedback or feature requests:
[email protected]
Or contact us via our official website:
https://www.minirpa.net
3.0.38 updates
. Action ConfirmIt optimisée : les messages flottent au centre de la page</p>
. Transformation d’affinement simple optimisée : prise en charge de l’utilisation d’espaces comme identificateurs d’ouverture et de fin</p>
. Fenêtre de travail optimisée : la fenêtre de travail normale et la fenêtre de travail incognito sont activées par défaut pour la notification
. Bug corrigé : Arrêtez l’instance en cours d’exécution une fois que les enregistrements dupliqués continus (distinction de champ unique) atteignent le seuil
. Bug corrigé : invite d’avertissement requise pour les zones de saisie
. Bug corrigé : problème avec l’action Open Field URL
. Bug corrigé : problèmes avec le filtre Ma recette
Latest reviews
- Sagi Brown
- Charged me falsely 35$ and wouldn't respond to my emails
- Bo Kjærgaard
- Seems connection to Google Sheets no longer work? The OAuth client was disabled on authentication
- Soufiane Ouakif Business
- 🔥You will feel like you have an AI that creates a workflow automation tools.🔥 Hi, I'm Soufiane, a Muslim from Morocco 🇲🇦, specializing in workflow automation through custom browser extensions. From auto-filling forms and performing repetitive tasks and scraping data, and more... I make your online work simpler and more efficient. **What Makes Us Stand Out?** With our expertise, you'll experience exceptional speed and efficiency in every project. We tackle even the toughest challenges and dedicate 100% of our focus to your task—no distractions. Our goal is not just profit but to free you from tedious tasks and ongoing costs, allowing you to focus on your major goals for quick, effective results. **Pricing Structure:** - Simple Projects: $50 - $100 - Medium Projects: $200 - $400 - Advanced Projects: $500 - $1000 - Monthly Subscription: $5k+ (for ongoing automation needs) # **How We Work:** - 1. Send us a video explaining the steps you want automated. - 2. We’ll analyze the project and provide an estimated price offer. - 3. We’ll develop the automation and send you a demo video. - 4. After payment, you’ll receive the final project. - 5. Lifetime VIP technical support. - 6. If you'd like, share your experience with us in a short video! - 7. We’ll be ready for your upcoming project requests! **We're Here for Any Inquiry!** - Have questions about automation or your upcoming project? Reach out, and we’ll respond quickly to provide the best solution for you. **Whatsapp for fast & direct contact : +212 628-330721**
- Duolinko Telbi
- The best one! Free version is enough for me.
- نـــدیم
- kindly fix the login issue
- Mahbub Rahman (Robin)
- A nice extension for scraping. But it is not completely free. Even then it works very well. In my case, sometimes it could not automatically go to the next page. It stopped after going to two pages. But, I tried again later. Then I was able to scrape up to many pages. But, again it stopped automatically after going to several pages. So I think it is a bug that needs to be fixed.
- Sunny
- Best from other scraping extensions, I scraped almost 750 movies data from IMDB in just minutes. Thank you for extension.
- TripleTree B. Hong
- really good. I tried several other add-ons, none of them extracted dynamic content completely except you. It would be better if there were more examples.
- Beyound Young
- Good extension
- Jacob Fenix
- Fantastic addon that's useless after one big scrape unless you pay an extortiate fee (and per month). Also requires you to sign up - should have been the first red flag. Avoid this one and find another.
- Katuki puong
- the new version is awesome!
- Anonymous
- nice. thanks
- Savage Susan
- Incredible tool and services. I can't code or use python. your YouTube videos helped me out. Plus plan is acceptable for me to scrape unlimited pages - worth it!
- sino House Thai
- Good
- tottooPatong
- Wow! the most powerful scraper! how to handle captcha during scraping?
- phofula kamala
- Great add-on and services, thank you Tracy.
- Kevin W
- Don't waste your time and money on it. It's a garbage. Poor documentation and no support.
- Anisur Rahman
- great extension.
- Anisur Rahman
- great extension.
- S Su
- 好用!
- Hoi Wai CHEUNG
- Only two columns of data can be extracted on the website, but the page display should be able to capture 8 columns of data. Why can’t this tool extract it? Site:www.valinonline.com
- Yuk Pui Joey TSANG
- If you don't register or log in, it is basically useless. Then you can use it for a while for free, and all subsequent functions will be charged, which is not worth it
- Kwok Yau KO
- There is no refund after payment, and the page crashes after a long time of crawling, so I don’t need this plugin anymore
- Manisha THAPA
- pourquoi ne peut-il pas être ouvert
- Rahul Kappor bhh
- It's too heavy to operate, and it charges, I can't use it anymore
- na li
- 真的特别好用!!!感谢了!!!
- cornercafebangkok
- Awesome. would be better if you support Safari.
- cornercafebangkok
- Awesome. would be better if you support Safari.
- chipotlle hnong
- By far the best addon!. There's 5 min learning curve at first. If you're familiar with HTML, CSS, it's extremely powerful and useful! Different from other scraper addon, this one can simulate manual surfing correctly, and handle various tricky cases. Kudos to you for making this!
- chipotlle hnong
- By far the best addon!. There's 5 min learning curve at first. If you're familiar with HTML, CSS, it's extremely powerful and useful! Different from other scraper addon, this one can simulate manual surfing correctly, and handle various tricky cases. Kudos to you for making this!
- Jesdaporn Jettrin
- the best data crawler. thank you team
- Jesdaporn Jettrin
- the best data crawler. thank you team
- Leon Rahmaan
- The best tool I have ever used to extract email address from pages. Easy to use, and best of all makes my work so much easier.
- Leon Rahmaan
- The best tool I have ever used to extract email address from pages. Easy to use, and best of all makes my work so much easier.
- Noam Hussain
- the tool is INTENSE AF, I'm using a free plan but the features feel un-right to be free. so time healing!
- Noam Hussain
- the tool is INTENSE AF, I'm using a free plan but the features feel un-right to be free. so time healing!
- Mushroom kids School
- awesome app and team. At first I just used it to collect public information and data from our own internal portal. Later, Tracy also guided me on how to automate my daily routine work. Now, the data collation and data entry tasks that I used to need two days a week now only take one hour to complete! It has unbelievably improved my work efficiency and allowed me to spend more time with my children. Thank you guys!
- Mushroom kids School
- awesome app and team. At first I just used it to collect public information and data from our own internal portal. Later, Tracy also guided me on how to automate my daily routine work. Now, the data collation and data entry tasks that I used to need two days a week now only take one hour to complete! It has unbelievably improved my work efficiency and allowed me to spend more time with my children. Thank you guys!
- 林凛
- 现在是无法登录了吗?都是403
- Yeshwant Bafna
- I dont have to mention more, everyone has already praised the product. But I must say more than the product, the team is just AMAZING. Their support and love and understanding of the product is outstanding. Just go for it and you will fall in love with the team and the product
- Yeshwant Bafna
- I dont have to mention more, everyone has already praised the product. But I must say more than the product, the team is just AMAZING. Their support and love and understanding of the product is outstanding. Just go for it and you will fall in love with the team and the product
- Carol kong
- 真的好强大!赞一个
- Joabe
- Looks good, but needs to create login. I hate having to create a new boring login.
- Joabe
- Looks good, but needs to create login. I hate having to create a new boring login.
- rouhao wang
- Pay carefully! Pay carefully! Pay carefully! Once paid cannot be refunded, some functions cannot be tested in the free version, and the plug-in crashes after running for about 5 minutes, which cannot be solved.
- rouhao wang
- Pay carefully! Pay carefully! Pay carefully! Once paid cannot be refunded, some functions cannot be tested in the free version, and the plug-in crashes after running for about 5 minutes, which cannot be solved.
- Fitness Equipment Haswell
- 建议把名称换成 “ minirpa迷你派采集器-最简单网页自动采集抓爬取监控” 方便搜索
- 陈俊钦
- 太强了, 居然是真的这么强, 太棒了
- Alexander Doak
- Fast support, really good functionality. In continual development, so it is improving over time. Some issues with data scraping stopping during internet outage, but they may be fixing that soon. Overall extremely useful. We have a paid subscription for almost a year now, and just upgraded to Pro.
- Alexander Doak
- Fast support, really good functionality. In continual development, so it is improving over time. Some issues with data scraping stopping during internet outage, but they may be fixing that soon. Overall extremely useful. We have a paid subscription for almost a year now, and just upgraded to Pro.