
BibItNow!
Extension Actions
Instantly generates a Bibtex, RIS, Endnote, APA, MLA or (B)Arnold S. bibliography item from journal articles, books, etc. .
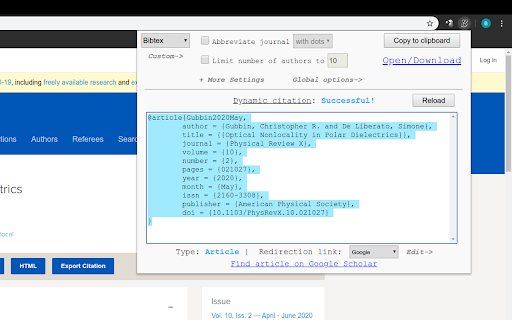
BibItNow! is a lightweight tool that focuses solely on extracting citation data from websites and formatting it into a bibliography item as quickly and as correctly as possible. Click the extension's tool bar icon or press the browser action shortcut keys when surfing on the abstract page of a journal article, a book, a thesis, or on any other web page, and the extension will try everything to extract all the data you want. In the format you like, with the encoding it needs! Decide whether you want to simply copy to clipboard, download a file or open it with the program of your choice!
Main Features
- Versatility: Generates bibliography items of journal articles, books, theses and generic web pages in the Bibtex, RIS, Endnote, APA, MLA, (B)Arnold S. or any user-defined format.
- Quick workflow: No more need to mess with the publisher's export button! One click or key stroke to extract the data and either show it in the popup (DEFAULT: ALT+C) , automatically copy it to clipboard (DEFAULT: Alt+W), or to download it as file (DEFAULT: ALT+Q). In the popup, a second click or key stroke lets you copy the data, open a redirection link or download/open the citation with your favorite library software. The extension furthermore comes with a set of options purely aimed at improving your workflow. For example, the plugin automatically generates a clickable and easily copyable DOI link if a DOI is found, or it can generate any other user defined link based on the available citation data. The plugin can also be configured to automatically highlight the citation text, enabling completely mouseless operation.
- Simplicity: The plugin only extracts, formats and exports bibliographic data, and its functions are only aimed at avoiding the most common nuisances in these three steps. No fancy library system included!
- Compatibility: An extensively tested set of fixed extraction and parsing rules combined with URL specific adjustments allows the plugin to work on abstract pages of many publishers, including Nature, Science, Elsevier, Springer and any publisher that cares to provide commonly formatted meta data. The extension furthermore works on journal article pages of the scientific databases PubMed and Scopus, and of the open access library arXiv. You can also cite books from various sources, such as Google books or the book section of Amazon!.
- Modifiability: Each citation format comes with a number of easily reachable and adjustable settings. Moreover, for the advanced user/contributor, the flexible data extraction and parsing system allows to easily add or improve the support for specific web pages. Add custom search queries via CSS selectors, and preprocess the extracted data. All in simple, URL-specific Javascript code.
- Optimized for Bibtex: Decide which bibliography field and how many authors to include, customize the bibkey, set whether to abbreviate the journal title and how to include URLs,. Special characters are automatically replaced by the corresponding Latex command, the format of names and initials is standardized, and math mode commands/formulas are preserved!
Credits/References
- XML formatted journal abbreviations are originally cited from the archive of the Woodward Library at the University Of British Columbia in Vancouver, Canada,
http://woodward.library.ubc.ca/research-help/journal-abbreviations/
from the JabRef list available here,
https://github.com/JabRef/abbrv.jabref.org/tree/master/journals
and from the list provided by "The Theta Foundation",
https://www.theta.ro/jot/res/serials_list/annser_A.html
- Publisher address information has been obtained and adapted from several sources.
1.) University of Leicester Publisher List:
https://www2.le.ac.uk/offices/english-association/yw/publishers
2.) Deutscher Bildungsserver:
https://www.bildungsserver.de/institutionen_de.html?Katego=11&Name=&Ort=&Land=0&Staat=0&Schlagwort=&suchen=finden
3.) Wiki publisher lists:
https://en.wikipedia.org/wiki/List_of_English-language_book_publishing_companies
https://de.wikipedia.org/wiki/Liste_deutschsprachiger_Verlage
- All latex commands for character replacements are cited from the XML Entity Definitions for Characters (3rd Edition) published by the W3C Math Working Group.
https://www.w3.org/2003/entities/2007doc/
- All non-numerical HTML entities are replaced using a lookup tabled cited from the Character Entity Reference Chart published by the W3C HTML Working Group.
https://dev.w3.org/html5/html-author/charref
- A list of unicode identities of all letter characters in all languages
is cited from the XRegExp library source:
http://xregexp.com/
- The extension popup uses the CSS style reset kindly provided by Meyerweb.
http://meyerweb.com/eric/tools/css/reset/
- UTF16 (non-BMP) characters are read using a function kindly provided by the Mozilla Developer Network.
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/charCodeAt
Latest reviews
- Ahmet M Elbir
- Please bring it back please
- asl res
- We want it back! It was so helpful. I hope you consider bringing it back!!
- John.Windland
- Noooo! I dont know how Im gonna live without you((( fk google
- Kristina F
- It was the best.
- edgrtrt weetdfr
- The best extension ever existed, please don't die
- Freddy Liu
- It does not handles url with _ properbly, need manual escape for urls like this
- Olivia Millington
- It's the closest I can get, but no citation exporter seems to be able to properly handle google patents. This pulls enough information that manually editing it later isn't too much of a hassle
- Olivia Millington
- It's the closest I can get, but no citation exporter seems to be able to properly handle google patents. This pulls enough information that manually editing it later isn't too much of a hassle
- Habib Yajam
- Best among the all extension for citing websites and papers in BibTeX format.
- Habib Yajam
- Best among the all extension for citing websites and papers in BibTeX format.
- fredrick soo (Freelance Writer)
- It does what it was intended to. Legit and free. Thanks developers.
- fredrick soo (Freelance Writer)
- It does what it was intended to. Legit and free. Thanks developers.
- Mio Vna
- 非常好用,点击可以自动下载enw,可以生成PPT可用格式,非常方便!!
- Nils Jansen
- This extension works really well. When used on a regular webpage, it provides data about the page itself, including the date of access. When e.g. a page about a scientific publication is opened, it parses information about the publication from the page and provides it for me to use. Great extension!
- Nils Jansen
- This extension works really well. When used on a regular webpage, it provides data about the page itself, including the date of access. When e.g. a page about a scientific publication is opened, it parses information about the publication from the page and provides it for me to use. Great extension!
- francesco vultaggio
- I use this extension daily and it's been amazing in grabbing the doi to create bibtext annotations. It also works very well in converting web pages. Highly recommended
- francesco vultaggio
- I use this extension daily and it's been amazing in grabbing the doi to create bibtext annotations. It also works very well in converting web pages. Highly recommended
- Huseyin Ahmetoglu
- I am using MacOs Monterey 12.3. When I add the extension to Chrome, I cannot use the '@' character anywhere in the browser. The problem is with this extension.
- Huseyin Ahmetoglu
- I am using MacOs Monterey 12.3. When I add the extension to Chrome, I cannot use the '@' character anywhere in the browser. The problem is with this extension.
- Meir Rosenblum
- Great! One suggestion, the date looks like this "yr/dd/mm/". Would be nice if it would not have the slash at the end and would be an option to do the aussie way "dd/mm/yr"
- Meir Rosenblum
- Great! One suggestion, the date looks like this "yr/dd/mm/". Would be nice if it would not have the slash at the end and would be an option to do the aussie way "dd/mm/yr"
- T Zou
- awesome! simiplicity is the best!
- T Zou
- awesome! simiplicity is the best!
- Cihan Kurt
- Sane defaults but very customizable.
- Cihan Kurt
- Sane defaults but very customizable.
- Christopher Menzel
- PhilPapers.org is a very important repository for philosophers but BibItNow! consistently misses page numbers when it constructs a BibTeX citation. Seems like there should be a simple fix.
- Christopher Menzel
- PhilPapers.org is a very important repository for philosophers but BibItNow! consistently misses page numbers when it constructs a BibTeX citation. Seems like there should be a simple fix.
- Matteo
- The best out there for bibtex
- Matteo
- The best out there for bibtex
- Brady Mattsson
- also works on amazon
- Brady Mattsson
- also works on amazon
- Ashish Gokarnkar
- Super Easy to use! And helped a lot in formulating my project. It works on all sites.
- Ashish Gokarnkar
- Super Easy to use! And helped a lot in formulating my project. It works on all sites.
- Dominik Pantak
- Best extension I've found for exporting to endnote
- Dominik Pantak
- Best extension I've found for exporting to endnote
- jenaya simpson
- It makes doing references for assessments so much easier! Share it around!
- jenaya simpson
- It makes doing references for assessments so much easier! Share it around!
- Zero Fung
- LOVE IT !!!!! Excatly what I want !!
- Zero Fung
- LOVE IT !!!!! Excatly what I want !!
- Steffen Martens (smartens)
- omg exactly what I want :) ... works great
- Steffen Martens (smartens)
- omg exactly what I want :) ... works great
- mingsong zhu
- Very useful and easy to use!But Mendeley web importer still more convenient than this.😟
- mingsong zhu
- Very useful and easy to use!But Mendeley web importer still more convenient than this.😟
- Billy Ireland
- very versatile. It is a shame that (in my case the .enw file) is always "generic". I wonder if there is a way to further fill in data. Other than that, this is an excellent project and in many ways, supersedes many citation tools that are designed professionally.
- Billy Ireland
- very versatile. It is a shame that (in my case the .enw file) is always "generic". I wonder if there is a way to further fill in data. Other than that, this is an excellent project and in many ways, supersedes many citation tools that are designed professionally.
- Bryn Hanks
- did not work
- Bryn Hanks
- did not work
- Adrian Wolkersdorf
- Extremely helpful to create APA sources from journal pages.
- Adrian Wolkersdorf
- Extremely helpful to create APA sources from journal pages.
- Muhammad Zain Gohar
- It has certainly made my life much much easier. Very useful and reliable! I am grateful!