
NoCodingデータスクレイパー - シンプルなWebスクレイピング
Extension Actions
- Extension status: Featured
- Extension status: In-App Purchases
ウェブページからデータをスクレイピングしてGoogleスプレッドシート、Excel、CSVファイルへデータを抽出します
+ 認証コード認識プラグイン (https://chromewebstore.google.com/detail/captcha-solver-free-auto/hlifkpholllijblknnmbfagnkjneagid) と連携して、自動認証中に複雑な認証コードの課題を解決できる機能を必要とする人に提供します。収集処理能力。
3クリックのみの簡単なノーコードWebスクレイパー!
メールクローラー、ウェブスクレイピングツール、ビジネスリードスクレイパーなどのインスタント無料レシピをターゲットウェブサイトから!
AIデータの検出と任意のWebサイトからのワンクリックによるデータ抽出を備えたインスタントデータスクレイパー!
登録のためのより多くのウェブ抽出とウェブスクレイピング機能!
さまざまなページ付けシナリオにコードを必要としない自動ページ付けWebスクレイピングツール!
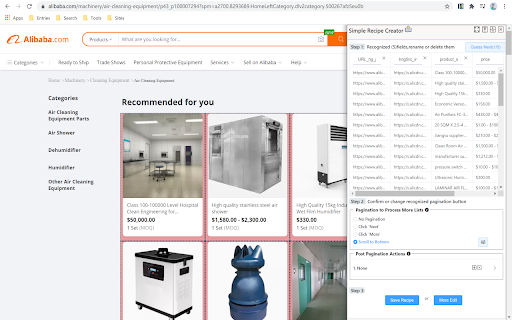
自動スクレイピングレシピの生成とビジュアルスクレイピングレシピの編集。
抽出されたすべてのデータは、二重保護によりローカルに安全に保存されます
スケジュールされたタスクを自動的に実行する簡単なWebクローラー
簡単なウェブスクレイパーまたはウェブクローラーとは何ですか?
NoCoding Data Scraper(NDS)は、Webデータをスクレイピングするためのシンプルなデータスクレイピングツールです。Webページを開き、NDSに表形式のWebデータとページネーションボタンを自動的に認識させ、Web抽出の前後に自動的に実行する追加のアクションをスクレイピングツールに指示します。予定されています。
また、簡単なWebスクレイパーは、画像URLを直接抽出する画像スクレイパーまたは画像クローラーにすることができます。NDSは、画像をバッチでスクレイピングし、ローカルまたはリモートクラウドに画像をダウンロードすることをサポートしています。
強力なウェブスクレイパーはどのように見えますか?
NDSは、セレクターを使用して要素コンテンツをインテリジェントに抽出し、[次へ]ボタンをクリックする、[さらに読み込む]ボタンをクリックする、ページを1つずつクリックする、下に無限にスクロールするなど、複数のページ付けモードをサポートします。NDSは、データのスクレイプとフローのサポートもサポートしています。パイプラインモードを介して複数のWebサイトを介してデータ。
オンラインビデオチュートリアル:https://www.youtube.com/channel/UCvcBbUXf_0Zj5_JR5U5n-MA
コア機能:
•ディープウェブスクレイピングと自動ウェブクロール
•要素のクリック、データ入力、およびWeb抽出を自動化するWebRPA
•AIを利用したウェブスクレイパーレシピの自動生成
•URLスクレイピングをバッチで実行するためのWebスクレイパーとWebクローラー
•検索エンジンのクエリと結果のスクレイピング用のWebスクレイパー
•簡単なページ付けモードをサポートするWebスクレイパー
•無限スクロールウェブスクレイピング
•柔軟なデータ変換と改良を備えたWebスクレイパー
•iFrameコンテンツスクレイピングをサポートするWebスクレイパー
•ローカルまたはクラウドストレージへの画像抽出機能とメールクローラー
•動的コンテンツスクレイピング用のWebスクレイパー(JavaScript + AJAX)
•インクリメンタルデータのスクレイピングとクロール
•GoogleSheet、Slack、その他のサードパーティアプリケーションとの統合
•99%のスクレイピングタスクに技術的なスキルは必要ありません
•ライブサポート、リモートレシピデバッグ支援、カスタムレシピ開発
いくつかの一般的な使用例:
*営業、不動産業者、ブローカーのビジネスリードスクレイピング、メールファインダー、または公衆電話スクレイピングを数分で
* Amazonの販売者、ディストリビューター、レビューアナリスト向けの価格監視とレビュー監視
*フリーランサーのためのパブリックディレクトリからの電子メールスクレイピング、アドレススクレイピングおよび電話スクレイピング
*自宅で作業するためのインテリジェントなデータ入力自動化とデータ抽出
*中小企業の所有者のためのクロスウェブサイトをスクレイピングする評価とレビュー
* Webスクレイピングツール+ SEO専門家向けのSEOツール
*採用担当者のスケジュールとして求職者を探す
NDSはどのように機能しますか?
Scraperは、公開Webページから電子メールやその他のテキストを収集できるデータ抽出およびコンバーターです。NDSは、CSSセレクターを使用してHTMLページの情報を識別し、レシピとタスクを定義するのに役立ちます。次に、その情報をスケジュールとしてスクレイプして保存します。結果は、後でCSVまたはXLSXファイルとして保存できるテーブル形式でブラウザに表示されます。NDSはUTF-8をサポートしているため、英語、日本语(日本語)、русский(ロシア語)、中文(中国語)、한국어(韓国語)などを簡単に使用できます。ツールを使用するのに、python、JavaScript、JSON、またはxPathのスキルは必要ありません。
WEBSCRAPERとWEBEXTRACTORの違い:
通常、Webスクレイパーの機能はWebエクストラクターの機能と似ています。どちらも、Webページからコンテンツをスクレイピングまたは抽出することです。ここで、NDSはデータのスクレイピングを支援するだけでなく、データの抽出、変換、およびクリーニングを行う機能も提供します。 。
NDSはEメールクローラーとして機能できますか?
はい。有料のメールクローラーはたくさんあります。NDSは、公開メールを自由に収集するためのメールスクレイピング方法を提供します。カスタムGoogle検索エンジン(CSE)と連携して、コードなしのレシピを定義し、CSE検索結果から公開メールを簡単に抽出できます。
NDSはビジネスリードスクレーパーとして機能できますか?
はい。NDSはリードスクレーパーとしてうまく機能します。キーワードを入力するレシピを定義してから、公開検索結果からリード情報をスクレイプできます。
NDSはRPAですか?
RPA(Robotic Process Automation)は、ユーザーがボットを定義して一連のアクションを自動的に実行できるようにするための一般的な概念です。デスクトップベースのRPAツールとは異なり、NDSはブラウザーベースの自動化ツールまたはWeb RPAに似ています。スクレイピングを除いて、次のことができます。スクロール、要素のクリック、またはフィールドの入力をシミュレートするさまざまなアクションを定義して、作業を簡単かつ高い生産性で実現します。
3.0.38 Updates
. 最適化された ConfirmIt アクション: メッセージがページの中央にフローティング</p>
. 最適化された単純な絞り込み変換: 開始識別子と終了識別子としてのスペースの使用のサポート</p>
. 最適化された作業ウィンドウ:通常の作業ウィンドウとシークレット作業ウィンドウは、通知のためにデフォルトでアクティブになります
. バグ修正: 連続した重複レコード (一意のフィールド区別) がしきい値に達すると、実行中のインスタンスを停止します
. 修正されたバグ: 入力ボックスに警告プロンプトが必要
. 修正されたバグ: [フィールドの URL を開く] アクションの問題
. バグ修正:マイレシピフィルターの問題
Latest reviews
- Sagi Brown
- Charged me falsely 35$ and wouldn't respond to my emails
- Bo Kjærgaard
- Seems connection to Google Sheets no longer work? The OAuth client was disabled on authentication
- Soufiane Ouakif Business
- 🔥You will feel like you have an AI that creates a workflow automation tools.🔥 Hi, I'm Soufiane, a Muslim from Morocco 🇲🇦, specializing in workflow automation through custom browser extensions. From auto-filling forms and performing repetitive tasks and scraping data, and more... I make your online work simpler and more efficient. **What Makes Us Stand Out?** With our expertise, you'll experience exceptional speed and efficiency in every project. We tackle even the toughest challenges and dedicate 100% of our focus to your task—no distractions. Our goal is not just profit but to free you from tedious tasks and ongoing costs, allowing you to focus on your major goals for quick, effective results. **Pricing Structure:** - Simple Projects: $50 - $100 - Medium Projects: $200 - $400 - Advanced Projects: $500 - $1000 - Monthly Subscription: $5k+ (for ongoing automation needs) # **How We Work:** - 1. Send us a video explaining the steps you want automated. - 2. We’ll analyze the project and provide an estimated price offer. - 3. We’ll develop the automation and send you a demo video. - 4. After payment, you’ll receive the final project. - 5. Lifetime VIP technical support. - 6. If you'd like, share your experience with us in a short video! - 7. We’ll be ready for your upcoming project requests! **We're Here for Any Inquiry!** - Have questions about automation or your upcoming project? Reach out, and we’ll respond quickly to provide the best solution for you. **Whatsapp for fast & direct contact : +212 628-330721**
- Duolinko Telbi
- The best one! Free version is enough for me.
- نـــدیم
- kindly fix the login issue
- Mahbub Rahman (Robin)
- A nice extension for scraping. But it is not completely free. Even then it works very well. In my case, sometimes it could not automatically go to the next page. It stopped after going to two pages. But, I tried again later. Then I was able to scrape up to many pages. But, again it stopped automatically after going to several pages. So I think it is a bug that needs to be fixed.
- Sunny
- Best from other scraping extensions, I scraped almost 750 movies data from IMDB in just minutes. Thank you for extension.
- TripleTree B. Hong
- really good. I tried several other add-ons, none of them extracted dynamic content completely except you. It would be better if there were more examples.
- Beyound Young
- Good extension
- Jacob Fenix
- Fantastic addon that's useless after one big scrape unless you pay an extortiate fee (and per month). Also requires you to sign up - should have been the first red flag. Avoid this one and find another.
- Katuki puong
- the new version is awesome!
- Anonymous
- nice. thanks
- Savage Susan
- Incredible tool and services. I can't code or use python. your YouTube videos helped me out. Plus plan is acceptable for me to scrape unlimited pages - worth it!
- sino House Thai
- Good
- tottooPatong
- Wow! the most powerful scraper! how to handle captcha during scraping?
- phofula kamala
- Great add-on and services, thank you Tracy.
- Kevin W
- Don't waste your time and money on it. It's a garbage. Poor documentation and no support.
- Anisur Rahman
- great extension.
- Anisur Rahman
- great extension.
- S Su
- 好用!
- Hoi Wai CHEUNG
- Only two columns of data can be extracted on the website, but the page display should be able to capture 8 columns of data. Why can’t this tool extract it? Site:www.valinonline.com
- Yuk Pui Joey TSANG
- If you don't register or log in, it is basically useless. Then you can use it for a while for free, and all subsequent functions will be charged, which is not worth it
- Kwok Yau KO
- There is no refund after payment, and the page crashes after a long time of crawling, so I don’t need this plugin anymore
- Manisha THAPA
- pourquoi ne peut-il pas être ouvert
- Rahul Kappor bhh
- It's too heavy to operate, and it charges, I can't use it anymore
- na li
- 真的特别好用!!!感谢了!!!
- cornercafebangkok
- Awesome. would be better if you support Safari.
- cornercafebangkok
- Awesome. would be better if you support Safari.
- chipotlle hnong
- By far the best addon!. There's 5 min learning curve at first. If you're familiar with HTML, CSS, it's extremely powerful and useful! Different from other scraper addon, this one can simulate manual surfing correctly, and handle various tricky cases. Kudos to you for making this!
- chipotlle hnong
- By far the best addon!. There's 5 min learning curve at first. If you're familiar with HTML, CSS, it's extremely powerful and useful! Different from other scraper addon, this one can simulate manual surfing correctly, and handle various tricky cases. Kudos to you for making this!
- Jesdaporn Jettrin
- the best data crawler. thank you team
- Jesdaporn Jettrin
- the best data crawler. thank you team
- Leon Rahmaan
- The best tool I have ever used to extract email address from pages. Easy to use, and best of all makes my work so much easier.
- Leon Rahmaan
- The best tool I have ever used to extract email address from pages. Easy to use, and best of all makes my work so much easier.
- Noam Hussain
- the tool is INTENSE AF, I'm using a free plan but the features feel un-right to be free. so time healing!
- Noam Hussain
- the tool is INTENSE AF, I'm using a free plan but the features feel un-right to be free. so time healing!
- Mushroom kids School
- awesome app and team. At first I just used it to collect public information and data from our own internal portal. Later, Tracy also guided me on how to automate my daily routine work. Now, the data collation and data entry tasks that I used to need two days a week now only take one hour to complete! It has unbelievably improved my work efficiency and allowed me to spend more time with my children. Thank you guys!
- Mushroom kids School
- awesome app and team. At first I just used it to collect public information and data from our own internal portal. Later, Tracy also guided me on how to automate my daily routine work. Now, the data collation and data entry tasks that I used to need two days a week now only take one hour to complete! It has unbelievably improved my work efficiency and allowed me to spend more time with my children. Thank you guys!
- 林凛
- 现在是无法登录了吗?都是403
- Yeshwant Bafna
- I dont have to mention more, everyone has already praised the product. But I must say more than the product, the team is just AMAZING. Their support and love and understanding of the product is outstanding. Just go for it and you will fall in love with the team and the product
- Yeshwant Bafna
- I dont have to mention more, everyone has already praised the product. But I must say more than the product, the team is just AMAZING. Their support and love and understanding of the product is outstanding. Just go for it and you will fall in love with the team and the product
- Carol kong
- 真的好强大!赞一个
- Joabe
- Looks good, but needs to create login. I hate having to create a new boring login.
- Joabe
- Looks good, but needs to create login. I hate having to create a new boring login.
- rouhao wang
- Pay carefully! Pay carefully! Pay carefully! Once paid cannot be refunded, some functions cannot be tested in the free version, and the plug-in crashes after running for about 5 minutes, which cannot be solved.
- rouhao wang
- Pay carefully! Pay carefully! Pay carefully! Once paid cannot be refunded, some functions cannot be tested in the free version, and the plug-in crashes after running for about 5 minutes, which cannot be solved.
- Fitness Equipment Haswell
- 建议把名称换成 “ minirpa迷你派采集器-最简单网页自动采集抓爬取监控” 方便搜索
- 陈俊钦
- 太强了, 居然是真的这么强, 太棒了
- Alexander Doak
- Fast support, really good functionality. In continual development, so it is improving over time. Some issues with data scraping stopping during internet outage, but they may be fixing that soon. Overall extremely useful. We have a paid subscription for almost a year now, and just upgraded to Pro.
- Alexander Doak
- Fast support, really good functionality. In continual development, so it is improving over time. Some issues with data scraping stopping during internet outage, but they may be fixing that soon. Overall extremely useful. We have a paid subscription for almost a year now, and just upgraded to Pro.